Laboratory mice, particularly the C57BL/6 strain, are essential animal models in biomedical research. However, accurate 3D surface motion reconstruction of mice remains a significant challenge due to their complex non-rigid deformations, textureless fur-covered surfaces, and the lack of realistic 3D mesh models. Moreover, existing visual datasets for mice reconstruction only contain sparse viewpoints without 3D geometries. To fill the gap, we introduce MoReMouse, the first monocular dense 3D reconstruction network specifically designed for C57BL/6 mice. To achieve high-fidelity 3D reconstructions, we present three key innovations. First, we create the first high-fidelity, dense-view synthetic dataset for C57BL/6 mice by rendering a realistic, anatomically accurate Gaussian mouse avatar. Second, MoReMouse leverages a transformer-based feedforward architecture combined with triplane representation, enabling high-quality 3D surface generation from a single image, optimized for the intricacies of small animal morphology. Third, we propose geodesic-based continuous correspondence embeddings on the mouse surface, which serve as strong semantic priors, improving surface consistency and reconstruction stability, especially in highly dynamic regions like limbs and tail. Through extensive quantitative and qualitative evaluations, we demonstrate that MoReMouse significantly outperforms existing open-source methods in both accuracy and robustness.
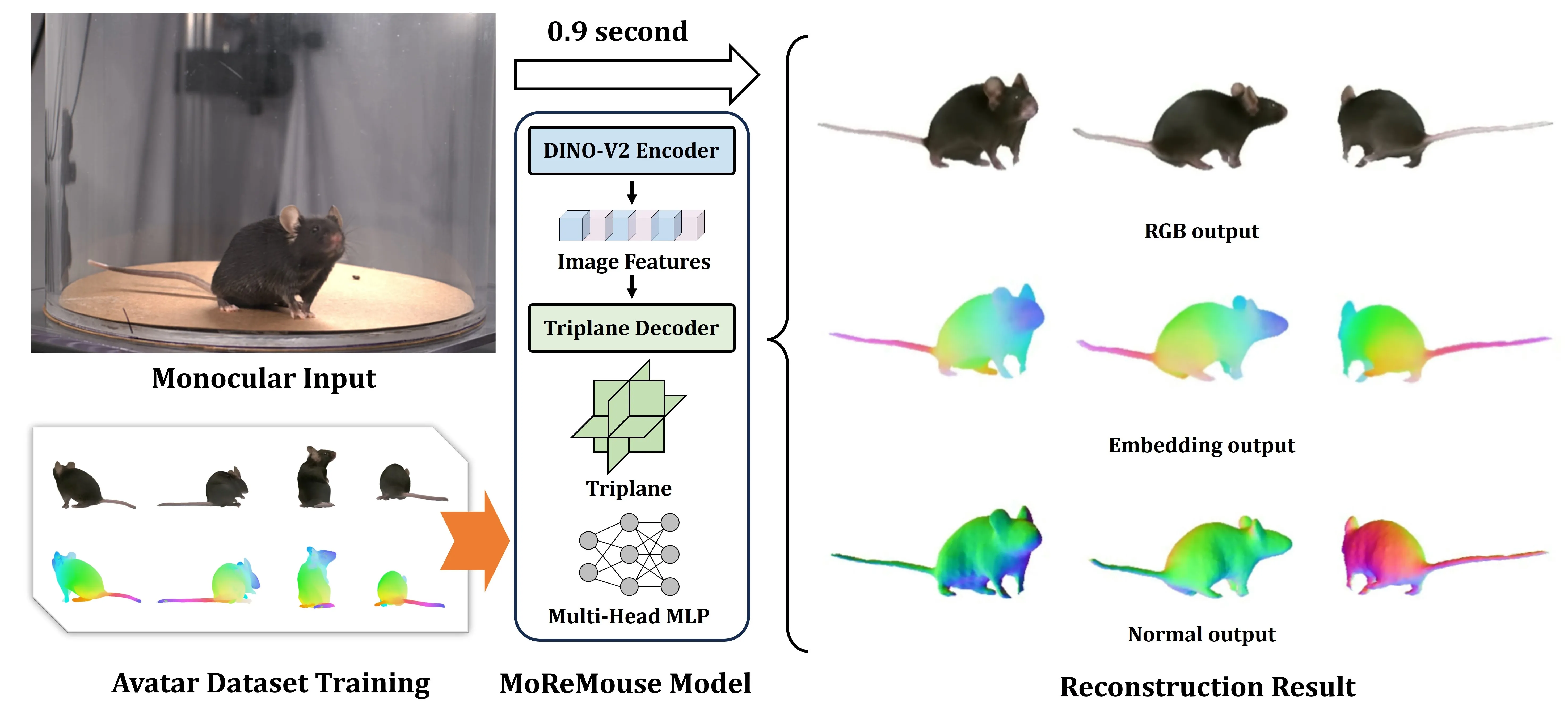
Given a single-view input (top-left, captured with an iPhone 15 Pro), MoReMouse predicts high-fidelity surface geometry and appearance within 0.9 seconds using a transformer-based triplane architecture (middle). To assist model training, we render a dense-view synthetic dataset by building the first Gaussian mouse avatar from sparse-view real videos (bottom-left). Our method outputs RGB renderings, semantic embeddings, and normal maps from a single image (right).
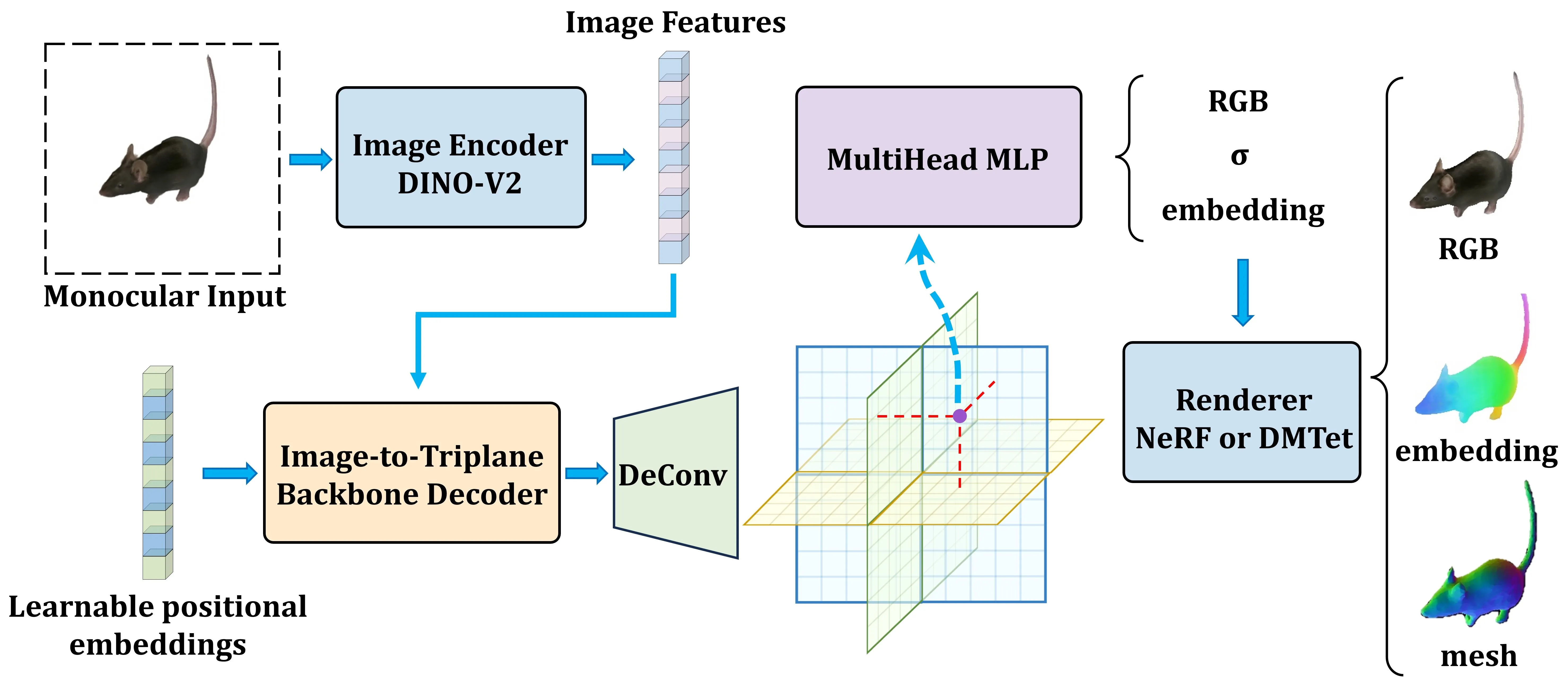
Given a monocular input image, a DINO-V2 encoder extracts high-level image features, which are processed by a transformer-based decoder to generate a triplane representation. These triplanes, combined with learnable positional embeddings, are queried by a Multi-Head MLP to predict per-point color, density, and geodesic embedding. Rendering is performed via either NeRF (for volumetric supervision) or DMTet (for explicit geometry output), producing RGB images, color-coded embeddings, and surface meshes.
Our synthetic dataset is built using a high-fidelity Gaussian mouse avatar. We begin by fitting a skeletal mesh model to multi-view recordings of real mice using 2D keypoints and silhouette constraints, resulting in anatomically plausible pose parameters . From this fitted mesh, we compute a baseline Gaussian position map in UV space, denoted as , where each valid texel corresponds to a Gaussian point.
To enhance this representation, a convolutional neural network (CNN) predicts:
The final deformed Gaussian positions are computed as:
where is the UV map of the neutral pose and is the LBS-based deformation function.
Finally, we render the avatar using Gaussian Splatting, producing diverse and photorealistic synthetic images for training monocular 3D reconstruction models.